Be careful how you use data structures!
Recently at work I came across a certain long-lived server process that was using an immense amount of memory over time. Every few days it would grow something over 10GB of resident memory, at which time we would restart the process. This was clearly not an ideal solution, especially because this specific server was running on something like eighty servers in forty data centers. So last week, during some relatively down time, I dug into where the memory was going. The first thing I did was spend some time with the heap profiler and heap checker from google’s perftools (https://code.google.com/p/gperftools/?redir=1) (side note – this is still on google code and not github!?). This showed nothing particularly useful. I then resorted to using valgrind on a test box, which, after an excruciatingly slow run, showed no leaks.
Well, I next spent a little time on code inspection, where I found that where there was one place where a leak was possible, it wasn’t likely to contribute to GB of leaked memory over days under the workloads that we have. And then the next thing I did was break out all the inputs to the server – client requests, plus data streams going into it. I went through these one at a time, and finally found that our primary data stream could easily raise the memory usage from a baseline of around 2GB to the 10 GB when I ran it through a test box at an accelerated rate.
Without going into too much detail, this data stream basically gives us a small number of data points for many pieces of data. These data sources usually each contribute their own data to the data point, and this data can change over time. So conceptually there is a two level data structure:
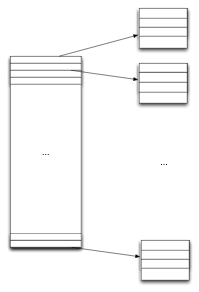
As it was written (disclaimer – I wrote much of the code in this server, but I don’t think I wore this part… although I may have) this was two levels, each implemented by c++11 std::unordered_map – which is essentially a hash table. The lower level map was defined in particular as std::unordered_map<std::string, Pod>. For the purposes of this article, the Pod type was this (and this is actually almost exactly what we were using:
struct Pod {
uint32_t item1{0};
uint32_t item2{0};
time_t timestamp{0};
};
A word about the strings – these were the host ids of the several servers providing the data. So in effect, every “bucket” in the upper level map had a map inside of it with the same several keys in it. Which meant that we were spending a lot of space on the keys. So the quick thing to do was to create an ancillary std::unordered_map<std::string,uint16_t> to map the hostname into integers and therefor the lower level maps become std::unordered_map<uint16_t,Pod>. Testing this showed that memory usage went down by around 3GB, which was a big saving. The math for removing the strings didn’t quite ever add up, but I was fairly happy. 3GB savings from 8GB is about 38% improvement, at the cost of one additional O(1) lookup per insertion. But maybe there was more to do. Why use a map at all when you have the same 5 keys there for *almost* every single lower level map. What if we just used a std::vector<Pod>? For this run the memory used was 5.4 GB below the baseline, or an additional 2.4 GB used. This was a savings of over 5GB, or over 60%!
It wasn’t obvious to me what was going on, so I wrote a little program to test a very simple scenario of allocating 10 million of the lower level “maps” with different strategies – std::unordered_map,std::map and std::vector. Here are the results for memory used compiling with both clang and g++ – all memory is in KB used, as reported by ps -ev on linux.

This gives results similar to my results for our production code at work. And it was at this point that I realized what was going on. When you create a hash table, it is not sized to the actual data in it - there is a lot of extra space used in the table for buckets that are not full - wasted space. This is not a big deal for a fairly dense hash table. However the vector was sized for the exact number of elements inside of it - there is still some overhead for the vector itself, but compared to the empty space in the hash table, it's not much. In hindsight this is fairly obvious, but it was not clear to me or my coworkers when I first started looking into this memory issue.
By the way, my test code is available here.